2021-常见问题收集整理-篇章1
一往情深深几许?深山夕照深秋雨。
简介:2021-常见问题收集整理-篇章1,完善自身技能树,有备无患。
一、顺序查找和二分查找法的时间复杂度分别为多少?
二分查找VS顺序查找图
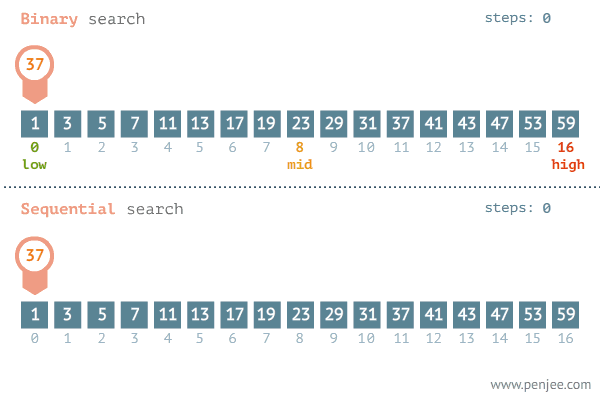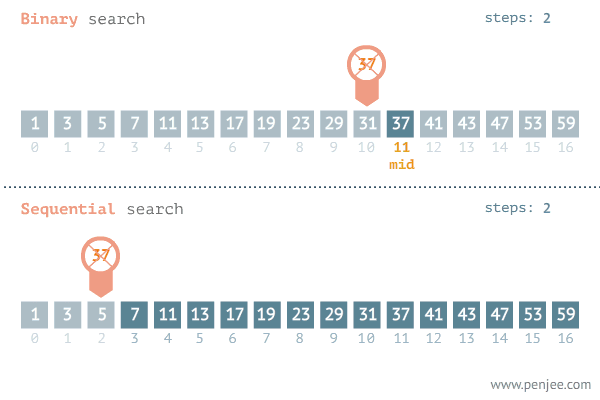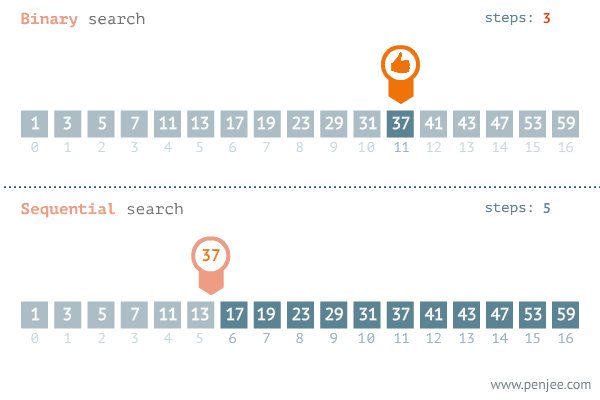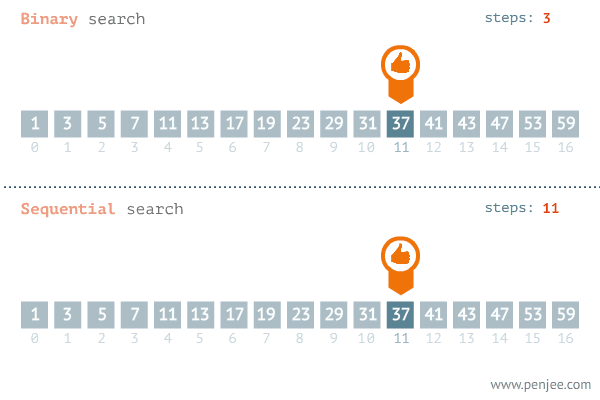
1、顺序查找
顺序查找的平均时间复杂度为O(logn),n 是待查数列的长度,因为顺序查找是从头到尾查找,而且是查找了整个数组。当然最好的情况是数组的第 1 个元素就是我们要找的元素,这样可以直接找到,最坏的情况是到最后一个元素时才找到或者没有找到要找的元素。
顺序查找代码:


1 /** 2 * 顺序查找 3 */ 4 public class SequentialSearch { 5 private int[] array; 6 public SequentialSearch(int[] array) { 7 this.array = array; 8 } 9 10 /**11 * 直接顺序查找12 * @param key13 * @return14 */15 public int search(int key) {16 for (int i = 0; i < array.length; i++) {17 if (array[i] == key) {18 // 找到了的话返回数组下标19 return i;20 }21 }22 return -1;23 }24 } View Code
2、二分查找
二分查找的时间复杂度为O(logn),利用折半查找大大降低了比较次数,它是一种效率较高的查找方法(redis、kafka、B+树的底层都采用了二分查找法 )。
二分查找的使用前提是线性表已经按照大小排好了序。这种方法充分利用了元素间的次序关系,采用分治策略。基本原理是:首先在有序的线性表中找到中值,将要查找的目标与中值进行比较,如果目标小于中值,则在前半部分找,如果目标小于中值,则在后半部分找;假设在前半部分找,则再与前半部分的中值相比较,如果小于中值,则在中值的前半部分找,如果大于中值,则在后半部分找。以此类推,直到找到目标为止。
二分查找代码:
1 package com.bebird.pms.controller.test; 2 3 /** 4 * 二分查找 5 * 假设在 2,6,11,13,16,17,22,30中查找22 6 */ 7 public class BinarySearch { 8 9 /**10 * 1、首先找到中值:中值为13(下标:int middle = (0+7)/2),将22与13进行比较,发现22比13大,则在13的后半部分找;11 * 2、然后在后半部分 16,17,22,30中查找22,首先找到中值,中值为17(下标:int middle=(0+3)/2),将22与17进行比较,发现22比17大,则继续在17的后半部分查找;12 * 3、然后在17的后半部分 22,30查找22,首先找到中值,中值为22(下标:int middle=(0+1)/2),将22与22进行比较,查找到结果。13 * @param args14 */15 public static void main(String[] args) {16 int arr[] = {2, 6, 11, 13, 16, 17, 22, 30};17 System.out.println("非递归结果,22的位置为:" + binarySearch(arr, 22));18 System.out.println("递归结果,22的位置为:" + binarySearch(arr, 22, 0, 7));19 }20 21 /**22 * 非递归23 * @param arr24 * @param res25 * @return26 */27 static int binarySearch(int[] arr, int res) {28 int low = 0;29 int high = arr.length - 1;30 while (low <= high) {31 int middle = (low + high) / 2;32 if (res == arr[middle]) {33 return middle;34 } else if (res < arr[middle]) {35 high = middle - 1;36 } else {37 low = middle + 1;38 }39 }40 return -1;41 }42 43 /**44 * 递归45 * @param arr46 * @param res47 * @param low48 * @param high49 * @return50 */51 static int binarySearch(int[] arr, int res, int low, int high) {52 53 if (res < arr[low] || res > arr[high] || low > high) {54 return -1;55 }56 int middle = (low + high) / 2;57 if (res < arr[middle]) {58 return binarySearch(arr, res, low, middle - 1);59 } else if (res > arr[middle]) {60 return binarySearch(arr, res, middle + 1, high);61 } else {62 return middle;63 }64 }65 }View Code
二、举例常见排序算法并说下快速排序法的过程,时间复杂度?
1、常见排序算法
八种常见排序算法:直接插入排序、希尔排序、简单选择排序、堆排序、冒泡排序、快速排序、归并排序和基数排序。
算法详情链接:https://www.cnblogs.com/taojietaoge/p/13599081.html
2、快排
快速排序使用分治的思想,从待排序序列中选取一个记录的关键字为key,通过一趟排序将待排序列分割成两部分,其中一部分记录的关键字不大于key,另一部分记录的关键字不小于key,之后分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
快速排序算法的基本步骤为(从小到大):
选择关键字:从待排序序列中,按照某种方式选出一个元素作为 key 作为关键字(也叫基准)。
置 key 分割序列:通过某种方式将关键字置于一个特殊的位置,把序列分成两个子序列。此时,在关键字 key 左侧的元素小于或等于 key,右侧的元素大于 key(这个过程称为一趟快速排序)。
对分割后的子序列按上述原则进行分割,直到所有子序列为空或者只有一个元素。此时,整个快速排序完成。
三、如何实现关键词输入提示功能?
使用字典树实现或HashMap。
1、Trie Tree简介
Trie Tree,又称单词字典树、查找树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。时间复杂度 : O(n),空间复杂度 : O(1)。
Trie Tree结构图
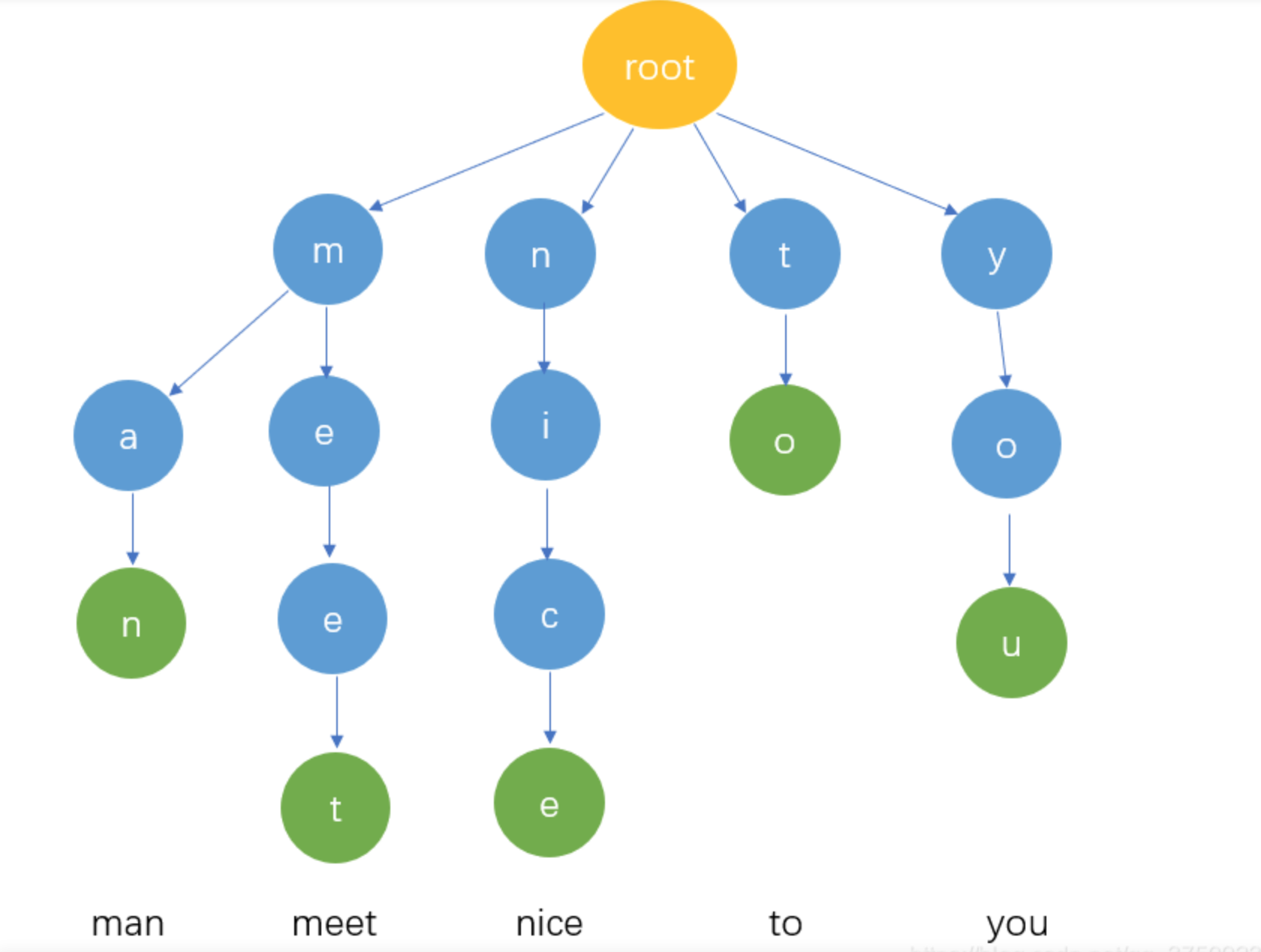
2、Trie Tree 性质
a. 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
b. 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
c. 每个节点的所有子节点包含的字符都不相同。
3、Trie Tree 分词原理
(1) 从根结点开始一次搜索,比如搜索【北京】;
(2) 取得要查找关键词的第一个字符【北】,并根据该字符选择对应的子树并转到该子树继续进行检索;
(3) 在相应的子树上,取得要查找关键词的第二个字符【京】,并进一步选择对应的子树进行检索。
(4) 迭代过程……
(5) 在直到判断树节点的isEnd节点为true则查找结束(最小匹配原则),然后发现【京】isEnd=true,则结束查找。
java 简单实现代码:
1 import java.util.HashMap; 2 import java.util.LinkedList; 3 import java.util.List; 4 import java.util.Map; 5 import java.util.Map.Entry; 6 7 /** 8 * trie tree 9 * 正向最大匹配 10 */ 11 public class TrieTreeDemo { 12 static class Node { 13 //记录当前节点的字 14 char c; 15 //判断该字是否词语的末尾,如果是则为false 16 boolean isEnd; 17 //子节点 18 List<Node> childList; 19 20 public Node(char c) { 21 super(); 22 this.c = c; 23 isEnd = false; 24 childList = new LinkedList<Node>(); 25 } 26 27 //查找当前子节点中是否保护c的节点 28 public Node findNode(char c){ 29 for(Node node : childList){ 30 if(node.c == c){ 31 return node; 32 } 33 } 34 35 return null; 36 } 37 } 38 39 static class TrieTree{ 40 Node root = new Node(' '); 41 42 //构建Trie Tree 43 public void insert(String words){ 44 char[] arr = words.toCharArray(); 45 Node currentNode = root; 46 for (char c : arr) { 47 Node node = currentNode.findNode(c); 48 //如果不存在该节点则添加 49 if(node == null){ 50 Node n = new Node(c); 51 currentNode.childList.add(n); 52 currentNode = n; 53 }else{ 54 currentNode = node; 55 } 56 } 57 //在词的最后一个字节点标记为true 58 currentNode.isEnd = true; 59 } 60 61 //判断Trie Tree中是否包含该词 62 public boolean search(String word){ 63 char[] arr = word.toCharArray(); 64 Node currentNode = root; 65 for (int i=0; i<arr.length; i++) { 66 Node n = currentNode.findNode(arr[i]); 67 if(n != null){ 68 currentNode = n; 69 //判断是否为词的尾节点节点 70 if(n.isEnd){ 71 if(n.c == arr[arr.length-1]){ 72 return true; 73 } 74 } 75 } 76 } 77 return false; 78 } 79 80 //最大匹配优先原则 81 public Map<String, Integer> tokenizer(String words){ 82 char[] arr = words.toCharArray(); 83 Node currentNode = root; 84 Map<String, Integer> map = new HashMap<String, Integer>(); 85 //记录Trie Tree 从root开始匹配的所有字 86 StringBuilder sb = new StringBuilder();; 87 //最后一次匹配到的词,最大匹配原则,可能会匹配到多个字,以最长的那个为准 88 String word=""; 89 //记录记录最后一次匹配坐标 90 int idx = 0; 91 for (int i=0; i<arr.length; i++) { 92 Node n = currentNode.findNode(arr[i]); 93 if(n != null){ 94 sb.append(n.c); 95 currentNode = n; 96 //匹配到词 97 if(n.isEnd){ 98 //记录最后一次匹配的词 99 word = sb.toString();100 //记录最后一次匹配坐标101 idx = i;102 }103 }else{104 //判断word是否有值105 if(word!=null && word.length()>0){106 Integer num = map.get(word);107 if(num==null){108 map.put(word, 1);109 }else{110 map.put(word, num+1);111 }112 //i回退到最后匹配的坐标113 i=idx;114 //从root的开始匹配115 currentNode = root;116 //清空匹配到的词117 word = null;118 //清空当前路径匹配到的所有字119 sb = new StringBuilder();120 }121 }122 if(i==arr.length-2){123 if(word!=null && word.length()>0){124 Integer num = map.get(word);125 if(num==null){126 map.put(word, 1);127 }else{128 map.put(word, num+1);129 }130 }131 }132 }133 134 return map;135 }136 }137 138 public static void main(String[] args) {139 TrieTree tree = new TrieTree();140 tree.insert("北京");141 tree.insert("海淀区");142 tree.insert("中国");143 tree.insert("中国人民");144 tree.insert("中关村");145 146 String word = "中国";147 //查找该词是否存在 Trid Tree 中148 boolean flag = tree.search(word);149 if(flag){150 System.out.println("Trie Tree 中已经存在【"+word+"】");151 }else{152 System.out.println("Trie Tree 不包含【"+word+"】");153 }154 155 //分词156 Map<String, Integer> map = tree.tokenizer("中国人民,中国首都是北京,中关村在海淀区,中国北京天安门。中国人");157 for (Entry<String, Integer> entry : map.entrySet()) {158 System.out.println(entry.getKey()+":"+entry.getValue());159 }160 161 }162 }View Code
四、HashMap 的实现原理?红黑树的结构?
1、从整体结构上...... 原文转载:http://www.shaoqun.com/a/876496.html 跨境电商:https://www.ikjzd.com/ 好卖家:https://www.ikjzd.com/w/776 焦点科技:https://www.ikjzd.com/w/1831 乐宝:https://www.ikjzd.com/w/2200
2021-常见问题收集整理-篇章1 一往情深深几许?深山夕照深秋雨。简介:2021-常见问题收集整理-篇章1,完善自身技能树,有备无患。一、顺序查找和二分查找法的时间复杂度分别为多少?二分查找VS顺序查找图1、顺序查找顺序查找的平均时间复杂度为O(logn),n是待查数列的长度,因为顺序查找是从头到尾查找,而且是查找了整个数组。当然最好的情况是数组的第1个元素就是我们要找的元素,这样可以直接
yiqu:https://www.ikjzd.com/w/210
灯塔计划:https://www.ikjzd.com/w/1281
去香港购物选购手机要注意什么?:http://www.30bags.com/a/404807.html
去香港国际机场DFS需要注意些什么?:http://www.30bags.com/a/404090.html
去香港还是去澳门买数码相机便宜?:http://www.30bags.com/a/403844.html
去香港黄大仙祠拜祭要注意些什么?:http://www.30bags.com/a/404353.html
闺蜜把我下面摸出水了 闺蜜用黄瓜折磨我过程:http://lady.shaoqun.com/m/a/248345.html
玩吧今天老师就是你的人 英语老师在宿舍满足了我:http://lady.shaoqun.com/m/a/248107.html
深圳有哪些好看的自然景观:http://www.30bags.com/a/501658.html
2021深圳求水山水上乐园开放了吗(服务时间):http://www.30bags.com/a/501659.html
男女都爱的八种姿势:http://lady.shaoqun.com/a/421139.html
女生包里有什么?公共场合14件私人好东西!你用过什么吗?:http://lady.shaoqun.com/a/421140.html
No comments:
Post a Comment